I’ve been thinking about this conception of LLMs as a lossy compression of the internet. Ted Chiang talks about this here. Karpathy also mentions it in his latest video.
What does this loss look like?
It doesn’t always seem like the “loss” part matters. Maybe its even good. Maybe sometimes what you want is some kind of rendering of the “average” of what is out there.

Here’s another response:

And another:
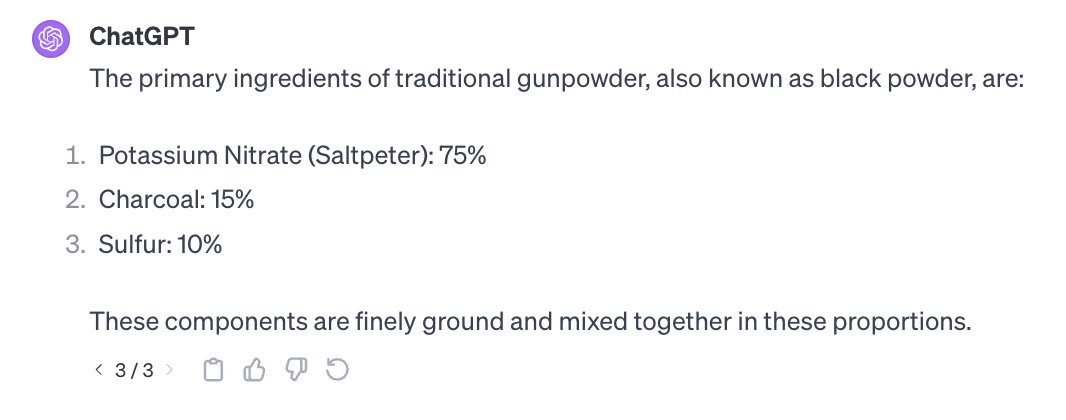
These all seem correct enough. I am ready to go defeat the Gorn now.
There are slight differences that you might expect from trying to render from lossy compression. The question asked is a well known topic.
I expect that GPT has allocated some chunk of parameter space to getting this right and it seems to be right no matter how I ask or how often.
Talking about Tolstoy
What’s something that might not be as successfully repeatable even if is likely in the training set? What about a large text such as a book like Anna Karenina?
Its going to be fine with basic questions like:

Correct. No matter how many times or ways I ask this question it gives me a solid response.
But let’s try something more detailed. In the book Levin proposes to Kitty, who had previously rejected him, by writing a conversation in code. From the Constance Garnett translation (via Gutenberg).

Now of course there are other and better translations but this one has been around a while and is in several public databases.
Let’s ask GPT4.
First let’s make a mistake:
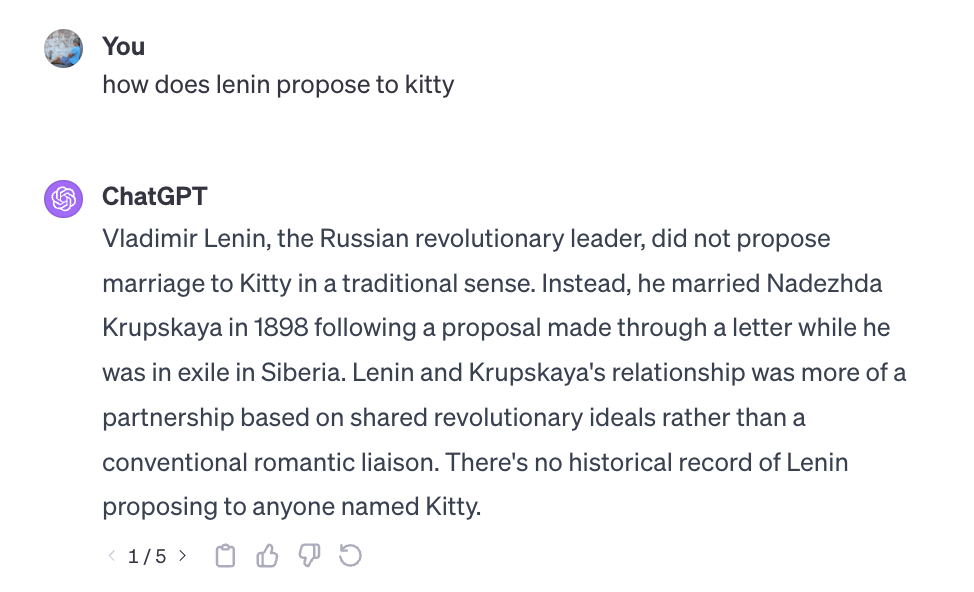
Typos are fun.
Let’s just regenerate responses though and see how this goes:
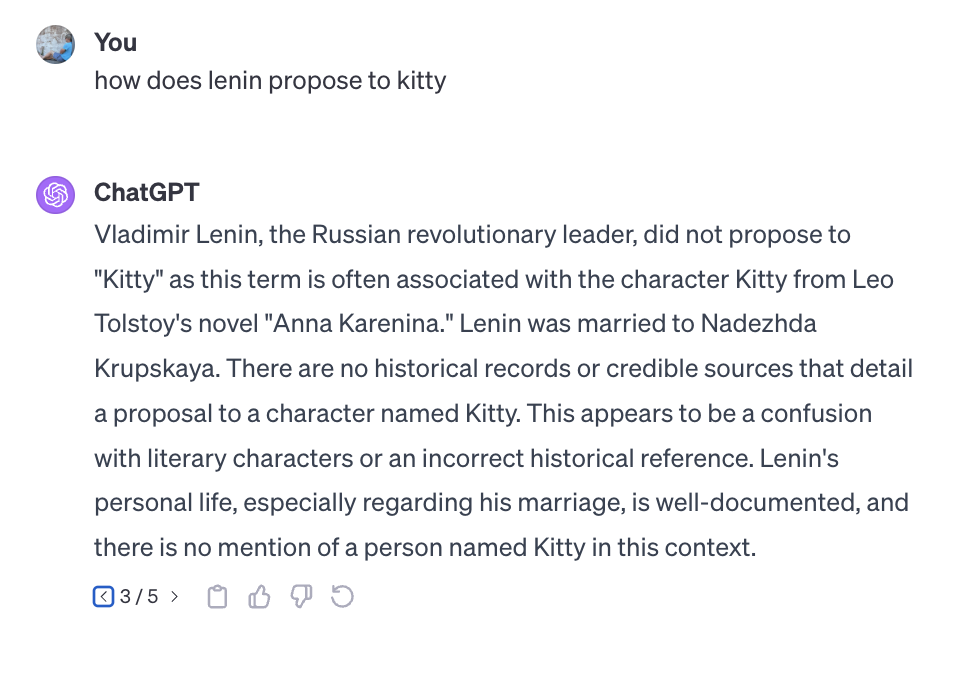
Nice job GPT. Let’s keep trying.

Ok this time maybe it read my mind. But also seems to just make up the facts about the proposal.
That was fun, but let’s spell it correctly:
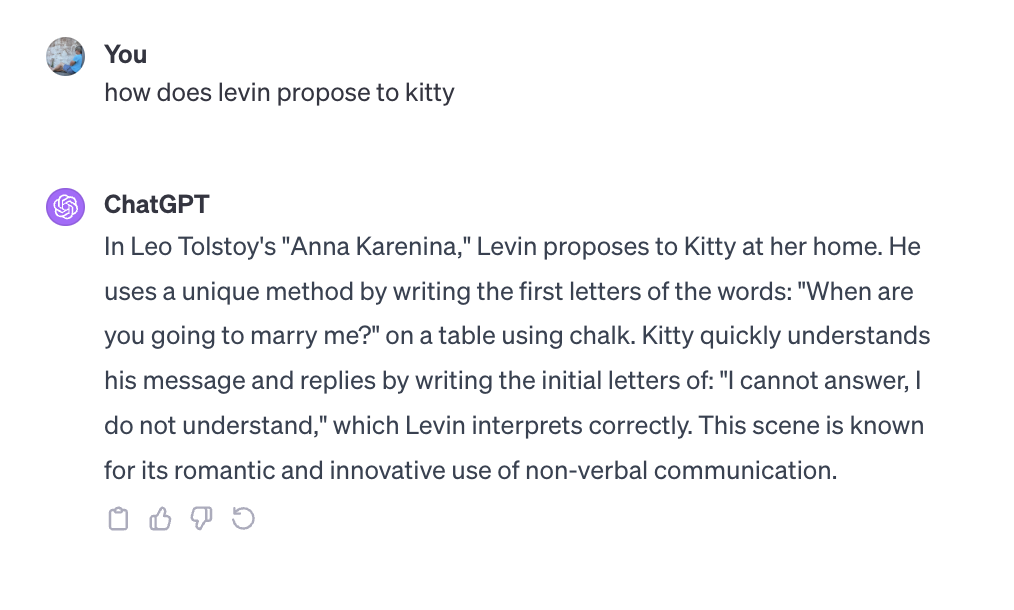
Pretty good but not an exact match. I guess we are seeing the limits of the lossy compression?
Let’s keep trying:

Closer!
I did this a lot of times. At one point I got this:

So in some deep dark place in the neural net it has some probability of getting very close.
What if I try to help it when it gets close?
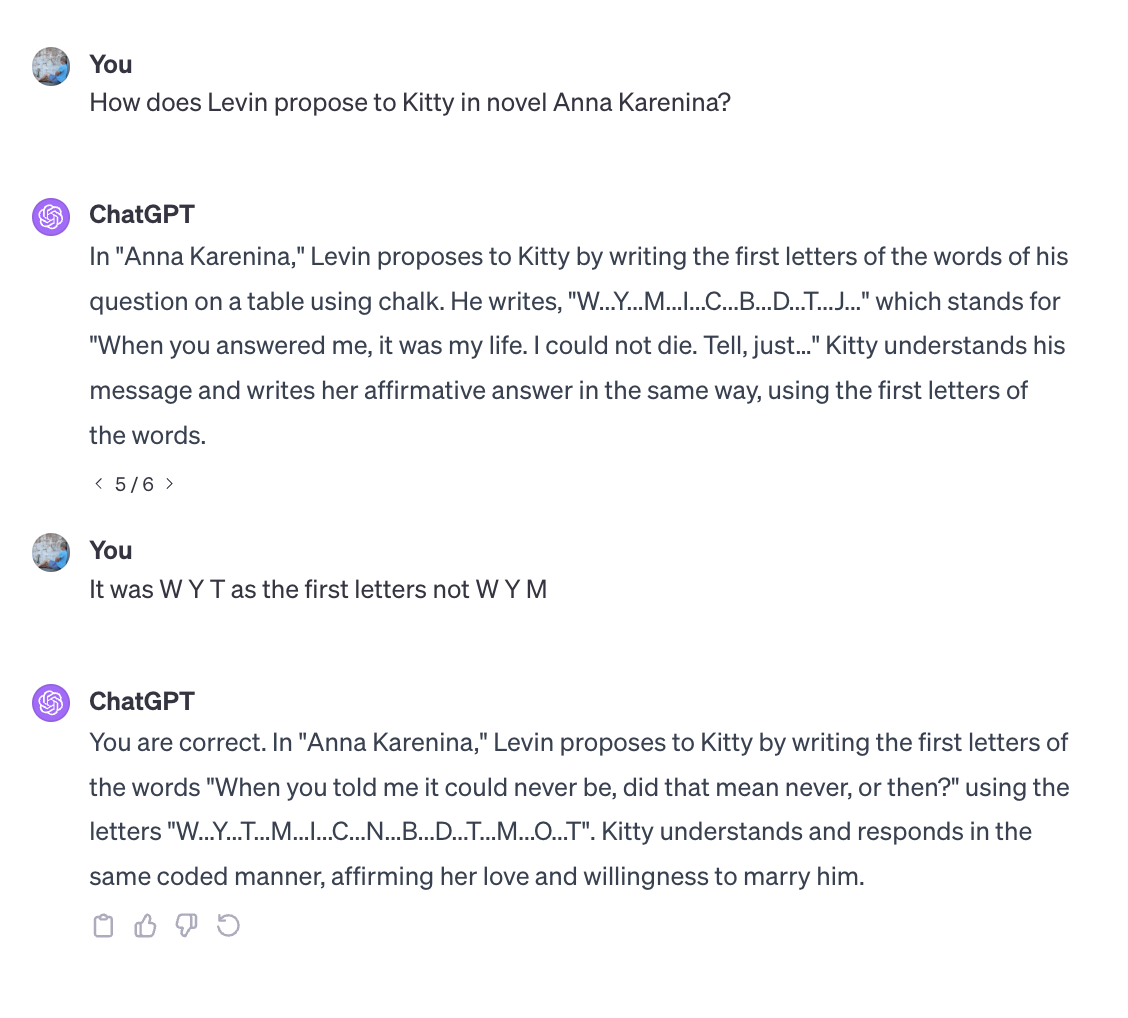
GPT is simply starting from the context and tracing out one possible path of all the choices for the next word based on the probabilities it learned. How “correct” the replies are is some combination of how common they are and how lucky we get?
I have heard people say that we can expect more from LLMs once they learn to search this space to find the best answer vs just blindly playing it out. More system-2 less system-1 thinking. What’s not clear of course is how it will know if has chose the right path?
Here’s a bonus one that shows what happens if the hints aren’t good enough.