
Part 1 of the series is here.
Machine learning and neural network systems have been around for a while but it seems like everything has really exploded in the last few years. We’ve gone pretty quickly from computers using AI to understand “Alexa, set a timer for 5 mins” most of the time, to worrying that AI is going to take everyone’s job or maybe take over the whole world.
Mostly this happened as a result of the development of LLMs or Large Language Models. These enormous models proved to be capable of many things which previous systems were not. What did it take to get them? Several things. Let’s walk through them.
We Got Better Designs for Neural Networks
Many people believe that the recent explosion in capability began with a scientific paper by some Google researchers in 2017 called Attention is All you Need which was in turn inspired by previous work such as AlexNet. I’m not smart enough to understand much/most of what is in the transformer paper but a key contribution was a specific way to organize neural networks called the Transformer architecture. Remember the diagram of the layered network from the last post? This is a much more sophisticated version of that. Here’s the diagram from their paper.
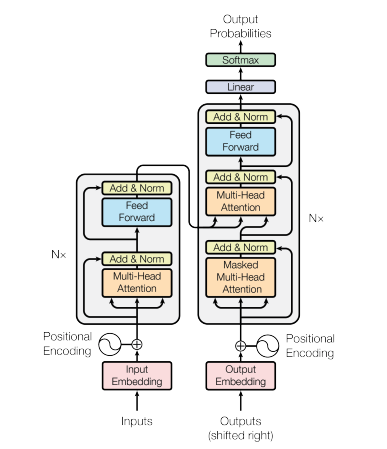
Each one of these boxes contains a lot of neurons.
I spent a lot of time going through an excellent YouTube series by Andrej Karpathy to try to get a better understanding of this design. At the end of this, I could convince myself that I kind of understood something about it, but I couldn’t keep it in my head for very long. There’s also a great series by 3Blue1Brown that digs into this more if you want to try to understand it better.
What we mostly need to know is that this design seems to work for systems which are very large by adding more and more of these transformers. It can efficiently make predictions based on a lot of data at once. It also seems to work well for all kinds of problems from cat detection to image generation, to writing an essay. Some people believe we can continue to make systems that are more and more intelligent just by adding more transformers while other people aren’t sure that we won’t need other breakthroughs.
But still this was 2017, so why did we just start hearing about all this stuff when ChatGPT (the first really popular LLM) launched about a year or so ago?
One thing people like to say is that it’s because Google fumbled their lead and didn’t try to capitalize on their invention well enough. Having worked at Google, this explanation seems like a pretty good one but it’s not the whole story..
The real story is there is also a lot more innovation that was needed to get to where we are today. Some of this was lying around at Google but other parts of it came from other places like Nvidia or OpenAI. The rest of this post and most of the next one will be talking about what it took to get from 2017 to something like ChatGPT.
For starters if you are going to make enormous transformer based models, then you are going to need more computing power to be able to train them.
More Computing Power
We might not be where we are today with AI if there were no video games. Video games drove innovations in computer hardware so that the games could be faster and more realistic. This led to the development of something called a GPU or Graphics Processing Unit. The basic idea for this was to provide many tiny processors on a chip that were very good at a particular kind of math that is needed to create realistic computer graphics. Gamers bought these cards up like hotcakes and companies like Nvidia made a lot of money selling them which funded more research and development.
The cards were so fast at doing math that people started trying to use them for other things besides computer graphics. During one of the major cryptocurrency crazes, these systems were quickly bought by individuals mining cryptocurrency, making it difficult for gamers to afford the latest GPUs.
AI researchers also realized the potential of using these GPUs to do all the math required for using large neural networks models. While companies like Nvidia didn’t really try to capitalize on the cryptocurrency boom (in fact they actually tried to cripple their devices’ ability to cryptocurrency), they did decide to start creating specialized versions of their GPU chips for doing AI. This along with similar developments by other companies, meant there was now a lot more processing power available for this kind of work.
But we still needed more data.
More Data
One thing which limits all machine learning (ML) systems is getting good data. When I was working on Alexa at Amazon, the ML team spent real money going around the US recording people talking with different accents in different environments. They needed all this data to train the models which took audio and detected the words people were saying.
In that project and others companies hired a bunch of workers to label data to create larger and larger training sets. Imagine people all over the world getting paid a few cents to look at photos and say things like “Cat” or “No Cat” for each one. This has been tried with almost any problem you can imagine. You can get a lot of good labeled data this way and use it to train a machine learning model.
The huge transformer models that GPUs enable need so much data to train them that these approaches don’t scale big enough. We would need too many humans and too much money to get the amount of data required. What we need are enormous datasets where we know the right answer without having to get people to tell us the answer. At first this seems counterintuitive. How can we know if there’s a cat in the image without a person to tell us? We can’t use the computer because we need these labeled images to train the computer in the first place.
One trick that people did was to realize there’s already a bunch of images that have labels on them. It’s a best practice on the internet to include captions or alt-text for images so that screen readers and other tools used by visually impaired people can know what is in the image. This information can be used as labeling for the image to train a model and even if it’s not perfect that sheer volume of this kind of data can produce good results. These kinds of models have been a key part of how AI systems are able to generate new images from simple text descriptions. So it’s at least partially true that if there were no visually challenged people, it would have been a lot harder to teach computers to create images. We’ll talk more about these text to image models in a later post.
Generating Streams of Text
For another example of how we’ve been able to scale up data sets to really large sizes, consider training a machine learning model which can predict what word will come next in a sentence. If we have access to a lot of text (say all the text on the internet) we already have a bunch of samples with which to train the model. We simply get a chunk of text and leave off the last word. Then we try to get the computer to predict it when we already know the answer. There’s a lot of digitized text out there in the world and we could grab and curate a whole bunch of it. This curation and filtering is still a lot of work but a lot of it can be automated. The systems built from this process are generally what we call LLMs.
This new problem is a little different than cat detection, there isn’t just one correct possible next word. We need to change our thinking from predicting Cat or NoCat to deciding (for every possible word) the probability that this word is next in the sequence.
For example, If the words so far are:
She threw the ____.
The word ball is pretty likely to be next, bat is also likely, but maybe (hopefully?) less so. Some words are probably very unlikely such as today which is hard to make sensical. Maybe: She threw the today show’s job offer in the trash.
Once we have the model we then evaluate it by giving it a sequence of words and asking it to compute for every word in the dictionary, how likely is it to be the next word. Instead of an output layer of Cat or NoCat we have thousands of outputs which represent how likely each possible word is to be next. We can choose to pick the most likely one or just “one of the most likely” if we want to mix it up a bit. We add that word to the sequence and start again by asking what comes next. If we keep repeating this process over and over we will generate a bunch of text that feels like a human wrote it.
In some sense what we have made is some kind of compression or average of all the things that have been read during training. The generation process might output verbatim some of the original text that was used in training or we might just get things which seem similar to many of the original texts but not exactly any of them. Some people have used the term Stochastic Parrots to describe these systems. Stochastic is just a fancy term for random, and it can seem like these systems are just randomly parroting back to us things it has heard but not understanding any of it.
In the next post we will talk about how this becomes something like ChatGPT. Here’s a hint: GPT stands for Generative Pre-trained Transformers. We use a Transformer model that has been Pre-trained on a lot of text to Generate new text.
Key Points
- Transformer models provided the design path for building much larger neural networks
- GPUs provided huge amounts of additional computer power to train these larger models
- People came up with clever ways to get very large datasets to train these models.
- Large Language Models or LLMs are trained from large datasets of text asking it to predict the next word
- We can use these models not just to predict things but also to generate content
Leave a Reply